Cálculo Electoral presenta un agregador de encuestas y el primer modelo de pronóstico electoral para las elecciones presidenciales de Ecuador. Algunos de los métodos que empleamos son tomados del trabajo que Nate Silver realiza en 538. Aquí describimos paso a paso de donde vienen los números que publicamos.
1. Agregador de Encuestas
La intención de voto de cada candidato (a la fecha de la última encuesta disponible) se lo obtiene siguiendo los siguientes cuatro pasos: recopilación de información, cálculo de ponderaciones para cada encuesta, homologación de resultados y estimación del promedio de intención de voto.
1.1. Recopilación de Información
Todas las encuestadoras que cumplan las siguientes dos condiciones serán incluidas: 1) estar habilitadas para publicar sondeos por el CNE, y 2) consultar tanto decisión como intención electoral. Si no encuentras alguna encuesta es por las siguientes razones: la empresa que la publica no está inscrita en el CNE, la encuestadora está registrada con un nombre diferente (nombre comercial diferente al de la razón social), o no la hemos incluido por desconocimiento.
Cada vez que aparezca publicado un nuevo sondeo, prestaremos particular atención a la metodología empleada por la empresa encuestadora, el ámbito en el que fue realizada la encuesta (nacional, provincial, urbana, rural, etc.), disponibilidad de información aportada durante el primer trimestre de 2017 (último semestre de 2016 en el caso de la primera vuelta), y de donde proviene el financiamiento.
1.2. Cálculo de Ponderaciones
Para poder calcular un promedio ponderado, debemos primero asignar pesos a cada encuesta. Utilizamos una escala de 100 puntos para calificar a cada encuesta en base a los siguientes cuatro criterios:
- Años de trayectoria de la empresa encuestadora
- Capacidad para predecir los comicios del 19 de febrero de 2017*
- Contribución metodológica
- Número de días a la fecha de la elección
*Para la primera vuelta, utilizamos la capacidad para predecir las Elecciones Presidenciales del 2013.
Los tres primeros criterios aporta equitativamente con 33.3 puntos. Los dos primeros están relacionados con la calificación de la encuestadora. El primero se basa en los años de experiencia de la empresa. Para calcular este peso, asumimos que podemos modelar una curva de aprendizaje usando una función que alcanza la asíntota de 33.3 exponencialmente de acuerdo a los años de experiencia. Hemos decidido usar una constante de tiempo de 5 años (esto quiere decir que empresas con 5, 10 y 40 años de trayectoria tendrán una calificación de 21.3, 29.3 y 33.3 puntos respectivamente). Para el segundo criterio, calculamos el valor absoluto de las diferencias entre el último sondeo de cada encuestadora (excluyendo el exit poll) y el resultado final para cada candidato en las elecciones presidenciales del 19 de febrero de 2017 (o Ecuador 2013 en el caso de la primera vuelta 2017). El complemento entre la suma de estos valores y 100% nos da una medida de la capacidad de predicción global para la elección en unidades de intención de voto. A la capacidad de predicción la normalizamos con respecto a 33.3, calificación que es obtenida por la empresa encuestadora con el menor error relativo medio.
Los dos últimos criterios se relacionan de manera más directa con el proceso electoral actual. Para estimar la contribución metodológica se toma en cuenta factores como disponibilidad de información de la encuestadora, el número de estudios nacionales y locales realizados dentro de la ventana temporal que es objeto del estudio, y disponibilidad de fichas metodológicas. La calificación de contribución metodológica evoluciona cada vez que aparecen nuevas encuestas. Finalmente, a la suma de los 3 primeros criterios le multiplicamos por una función exponencial que hace las veces de filtro temporal. La constante de tiempo de este filtro es de 90 días, lo que quiere decir que una encuesta publicada el día de hoy tienen 2.7 veces más influencia que una publicada hace 90 días.
1.3. Ajustes para Homologar Encuestas
Para la segunda vuelta prevemos que algunas encuestas publicarán resultados en base a votos totales, con información sobre nulos, blancos, nivel de decisión y como se distribuyen los indecisos. Estas encuestas no solo que tendrán mejor calificación en la ponderación de contribución metodológica, sino que también marcarán la pauta para distribuir a la fracción de indecisos de las encuestadoras que no reporten esta información.
Las encuestas serán homologadas de acuerdo al siguiente procedimiento: 1) multiplicamos la intención de voto de cada una de las cuatro categorías (dos candidatos, nulos y blancos) por la fracción de entrevistados que ya han decidido por quien votar; 2) como las encuestas ya no suman 100%, hemos creado una categoría a la que la denominamos indeterminados: 100% - suma de todas las categorías; 3) asignamos a los indeterminados de acuerdo al estudio más reciente que se haya realizado sobre el voto indeciso; y 4) a los indecisos que votaron nulo o blanco en la encuesta se los distribuirá equitativamente entre los dos candidatos. Una vez que los indeterminados han sido considerados podemos normalizar para votos válidos (es decir, remover del universo de votantes a nulos y blancos).
Estos ajustes son necesarios porque no todas las encuestas publicadas suman 100%, y no hay un estándar para tratar categorías como nulos, blancos, ninguno, no conoce, no sabe y otros. Además, cada encuestadora tiene metodologías diferentes para aproximarse a los indecisos. Para poder elaborar nuestros modelos y pronósticos, hemos decidido homologar los sondeos en base a dos escenarios:
Escenario con Incidencia de Indecisos
En este escenario, multiplicamos la intención de voto de cada candidato por la fracción de entrevistados que ya han decidido por quien votar. Como las encuestas ya no suman 100%, hemos creado una categoría a la que la denominamos indeterminados: 100% - suma de todas las categorías. Asignamos parte de los indeterminados a nulos y blancos de acuerdo a la tendencia. El sobrante de los indeterminados lo dividimos en dos. La primera mitad lo distribuimos a cada candidato de acuerdo al promedio anterior de intención de voto. La otra mitad la distribuimos equitativamente entre: 1) todos los candidatos que tengan al menos 6.25% de intención de voto, y 2) un sólo grupo que congrega a todos los candidatos por debajo de 6.25%. Los candidatos en este grupo recibirán entre todos la asignación equivalente a la que le toca a los candidatos con más opciones. Una vez que los indeterminados han sido considerados y con la nueva estimación ajustada del total de nulos y blancos, podemos normalizar para los votos válidos.
Escenario sin Incidencia de Indecisos
A pesar de que hemos decidido utilizar únicamente sondeos que consultan tanto intención electoral como indecisión de voto, en este escenario no utilizamos la información sobre indecisión. Cada sondeo debe incluir información sobre nulos y blancos, y la suma de todas sus categorías debe ser igual a 100%. De no cumplirse la segunda condición, aplicamos una primera normalización tratando por igual a todas las categorías. Después de este ajuste, normalizamos los porcentajes de cada uno de los candidatos con respecto a los votos válidos (es decir, dividir para la suma de % votos totales - % nulos - % blancos).
1.4. Promedios Ponderados
El estimado de la intención de voto para la segunda vuelta electoral se lo obtiene a través de un estimador lineal, que minimiza el error cuadrático medio (LMMSE), en función de los resultados de la primera vuelta, lecturas de encuestadoras y la calificación de cada sondeo. La implementación de este estimador está descrita en los ejemplos 2 y 3 del artículo de wikipedia sobre MMSE. Como aplicamos este algoritmo a nivel de votos válidos (y que han sido previamente homologados), sólo es necesario estimar la intención de voto para uno de los candidatos. Suponemos que la votación de Moreno caerá en el rango entre 39.4 y 72%. Esta suposición nos permite inicializar el estimador lineal con una distribución uniforme continua cuyo dominio esta definido por el mínimo y máximo de este rango. El momento que conozcamos de algún nuevo sondeo, lo someteremos al procedimiento descrito en los pasos anteriores para evaluar su ponderación y distribuir a los indeterminados. Una vez que contamos con el peso del sondeo (que para este estimador es proporcional al inverso del cuadrado de la calificación) y el valor de preferencia electoral homologado, podemos entonces incluirlo en el estimador lineal y actualizar el estimado de la intención de voto.
El estimado de la intención de voto es el resultado de un promedio con pesos de las encuestas seleccionadas. El promedio se lo realizará individualmente para cada candidato. El momento que conozcamos de algún nuevo sondeo, lo someteremos al procedimiento descrito en los pasos anteriores para poder actualizar el estimado de la intención de voto.
2. Pronósticos
Reportaremos pronósticos en base a nuestro análisis de como evolucionan las tendencias de cada candidato, y además, estudiaremos las principales fuentes de incertidumbre para poder simular la elección miles de veces. Al clasificar los resultados de estas simulaciones, podremos estimar la probabilidad de posibles desenlaces de la contienda electoral.
2.1. Cálculo y Ajuste de Tendencias
La cantidad de estudios compilados será mucho menor durante el balotaje. Pero a pesar de aquello, estaremos atentos a cualquier tendencia que se pueda producir durante los últimos días de campaña. Aplicaremos un modelo de regresión local directamente sobre los resultados del estimador lineal en función del tiempo. Procuraremos utilizar funciones con pocos parámetros y de bajo orden, para evitar efectos no lineales en extrapolaciones al día de la elección. Nos aseguraremos de que la sumatoria de cada punto (en el tiempo) de las líneas de tendencia sume 100%, y que sea posible para ambos candidato ganar o perder votos.
El modelo hace comparaciones entre diferentes ediciones de la misma encuestadora. Por ejemplo, si Perfiles de Opinión registra que el binomio Moreno-Glas tiene un 48% de intención de voto en el mes de octubre y obtiene un 51% en una versión de la encuesta con similar metodología durante el mes de diciembre, esto sugiere que Moreno ganó 3 puntos porcentuales. Si hay suficientes datos, realizaremos estas comparaciones para cada binomio y encuestadora por separado. Luego, tomaremos estas comparaciones y trazaremos una línea de tendencia haciendo uso de una regresión local. Estas tendencias por encuestadora nos ayudaran a decidir como calcular las tendencias conforme aparece un nuevo punto en el agregador de encuestas. Si esta información no esta disponible, haremos una regresión local directamente sobre los puntos que aparecen en el agregador de encuestas (independientemente de la encuestadora). Procuraremos utilizar funciones con pocos parámetros y de bajo orden, para evitar efectos no lineales en las extrapolaciones. Nos aseguraremos de que la sumatoria de cada punto (en el tiempo) de las líneas de tendencia sume 100%, y que sea posible para cada candidato ganar o perder votos. En estas elecciones esperamos que las tendencias se vayan definiendo conforme va cambiando el nivel de indecisión.
Para probar nuestra metodología hemos aplicado el modelo a los datos publicados por wikipedia en sus artículos sobre las elecciones presidenciales de Ecuador 2013, alcaldía de Quito 2014, y la primera vuelta de las elecciones de Argentina 2015. La tabla que esta a continuación tiene las proyecciones de la suma de nulos y blancos para cada una de estas elecciones, y su comparación con los resultados finales.
Elección
NB
Pronóstico NB
Diferencia
Presidente Ecuador 2013
9.1 %
6.3 %
2.8 %
Alcalde Quito 2014
7.5 %
6.4 %
1.1 %
Presidente Argentina 2015 (1era vuelta)
3.4 %
2.0 %
1.4 %
NB = Nulos + Blancos
Estos resultados demuestran que el tratamiento que damos a los datos para homologarlos fue adecuado. Obviamente esto no garantiza que nuestra metodología funcione siempre, y estaremos ajustando nuestros parámetros (por ejemplo, el asignar la mitad de los indeterminados de acuerdo a la tendencia) conforme ganemos experiencia analizando más y más elecciones. La elección de la alcaldía de Quito es sumamente interesante ya que la indecisión se mantuvo alta y constante hasta 20 días antes de las elecciones. La suma de nulos y blancos rodeaba el 14%, bajó al 11% faltando 13 días, y nuestra extrapolación proyecta 6.4% al día de las elecciones. Similar tratamiento a la evolución de la intención de voto de Mauricio Rodas, nos da 29% a 20 días de las elecciones, 37% faltando 13 días, y la extrapolación al día de las elecciones fue del 51% (con una desviación estándar ponderada del 10%). Rodas obtuvo el 59% de los votos válidos.
2.2. Estimación de la Incertidumbre
La mayor fuente de incertidumbre en la segunda vuelta son el 32.6% de votos válidos que no se inclinaron ni por Moreno, ni por Lasso. A pesar de que probablemente el nivel de indecisión vaya disminuyendo a medida que se acerca el día de la elección, el estimador lineal que hemos escogido sólo toma en cuenta la incertidumbre inicial; y en este caso esperamos que sea precisamente 32.6%.
Una vez que contamos con una línea de tendencia para cada candidato, la substraeremos de los puntos del agregador de encuestas. Tomamos la desviación estándar ponderada de este resultado para tener una idea del margen de error de nuestros pronósticos. Cuando los modelos de regresión y los promedios de las encuestas muestran diferencias significativas, esto significa que hay demasiada incertidumbre.
2.3. Generación de Trayectorias
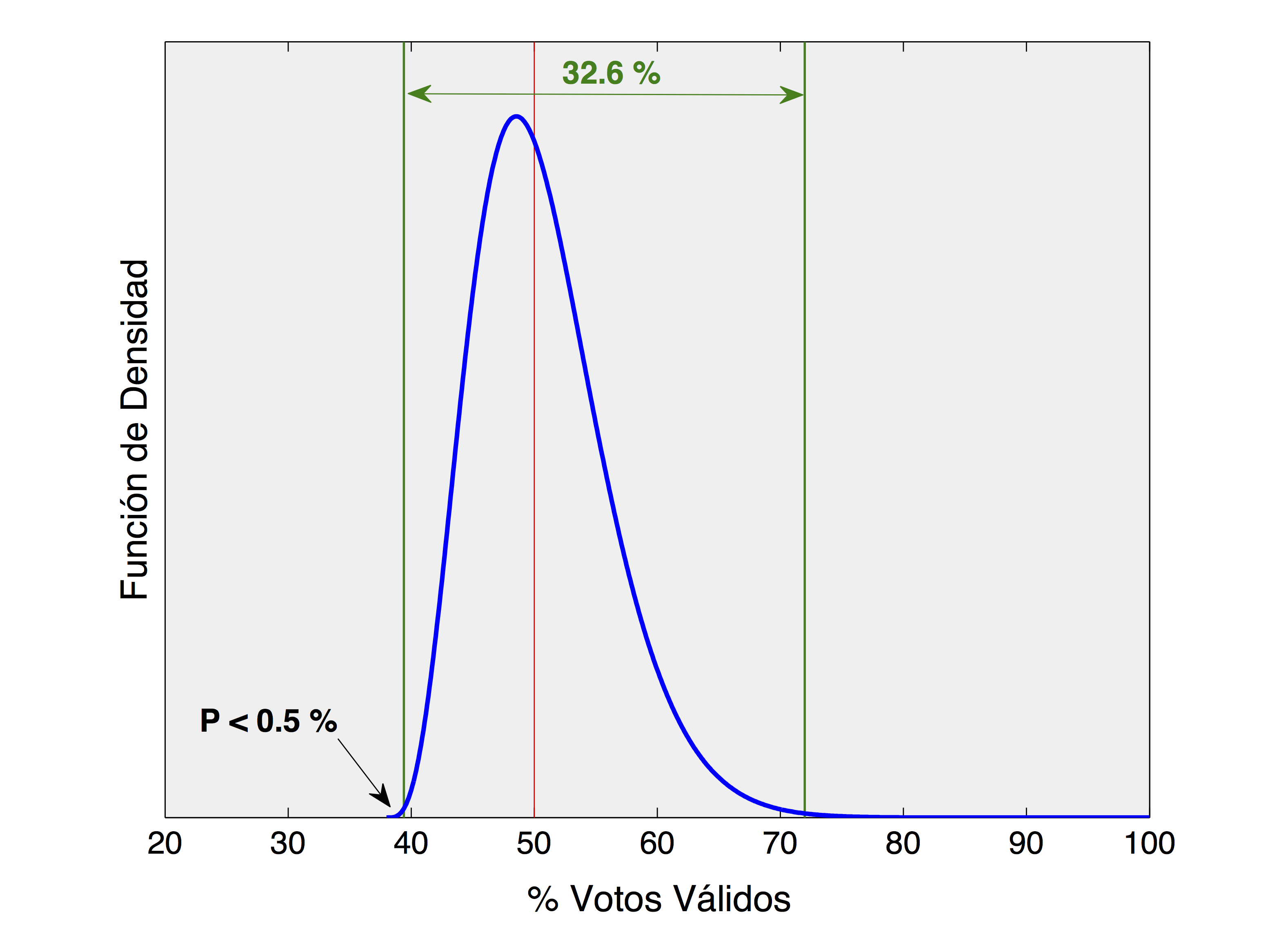
Utilizamos una distribución de probabilidad beta definida de tal manera que refleja las siguientes tres características: 1) la mediana de la función de densidad coincide con el promedio proyectado de la intención de voto; 2) hay una probabilidad de menos de 0.5% de que Moreno obtenga menos votos que en la primera vuelta; y 3) la distribución se extiende de tal manera que es posible para Moreno captar a todos los indecisos (aunque altamente improbable). A continuación una visualización de dicha distribución beta:
Ejemplo de distribución beta empleada para generar posibles resultados de la votación de Moreno. Las lineas verdes marcan el rango más probable de resultados y la linea roja marca la mediana de la función de densidad de probabilidad.
A partir de esta distribución podemos simular la elección miles de veces. Al resultado de cada una de estas simulaciones la llamaremos trayectoria.
Una vez que tenemos la proyección de la intención de voto (al día de las elecciones) y un estimado de la incertidumbre, podemos simular la elección miles de veces. Al resultado de cada una de estas simulaciones la llamaremos trayectoria. Utilizamos una distribución de probabilidad beta, cuyos parámetros alfa y beta son calculados en base al promedio proyectado y desviación estándar ponderada para cada candidato. Consideraremos en un futuro utilizar distribuciones t, ya que teóricamente son más apropiadas cuando las muestras son pequeñas. Además, estas tienen colas más largas que una distribución normal, o una beta. Esto es cierto particularmente para distribuciones t con pocos grados de libertad. En este momento es difícil decidir el número de grados de libertad que se debe emplear, ya que no tenemos suficientes datos para saber como se comporta la cola de la distribución. Por ejemplo, ¿cuál es la probabilidad de que un candidato que va perdiendo por 20 puntos en las encuestas termine ganando la elección? La respuesta podría cambiar por varios ordenes de magnitud (1, 0.1 ó 0.01% chances de ganar) dependiendo de cuantos grados de libertad se utilicen en la distribución t. Una distribución t bien parametrizada ayudaría a modelar de mejor manera estos casos extremos.
2.4. Cálculo de Probabilidades
En cada trayectoria nos haremos las siguientes preguntas: ¿quién ganó la presidencia?, y ¿cuál es la diferencia porcentual en términos de votos válidos entre los dos candidatos?. Las probabilidades que publicamos son obtenidas al contar el número de trayectorias de similares respuestas y dividiéndolas para el total de trayectorias generadas (N = 50000).
En cada trayectoria nos haremos las siguientes preguntas: ¿hay segunda vuelta?, y ¿cuáles son los dos binomios que aparecen en los primeros lugares?. Contando el número de trayectorias de similares respuestas y dividiendo para el total de trayectorias generadas, podemos estimar probabilidades.
Errores y Omisiones
Intentamos evitar manipular el modelo una vez que se publica, pero siempre estamos atentos a errores. Si hay cambios significativos en el modelo, los divulgaremos aquí.