Nivel de acierto de las encuestas para las alcaldías 2019 de Quito, Guayaquil y Cuenca.
Al comparar los resultados de las elecciones para las alcaldías de Quito, Guayaquil y Cuenca con los números difundidos por encuestadoras hasta 10 días antes del 24 de marzo, podemos observar que las preferencias electorales para Quito y Cuenca poco concuerdan con el resultado electoral. Estas discrepancias pueden explicarse por una variedad de factores que trataremos de identificarlos en este análisis.
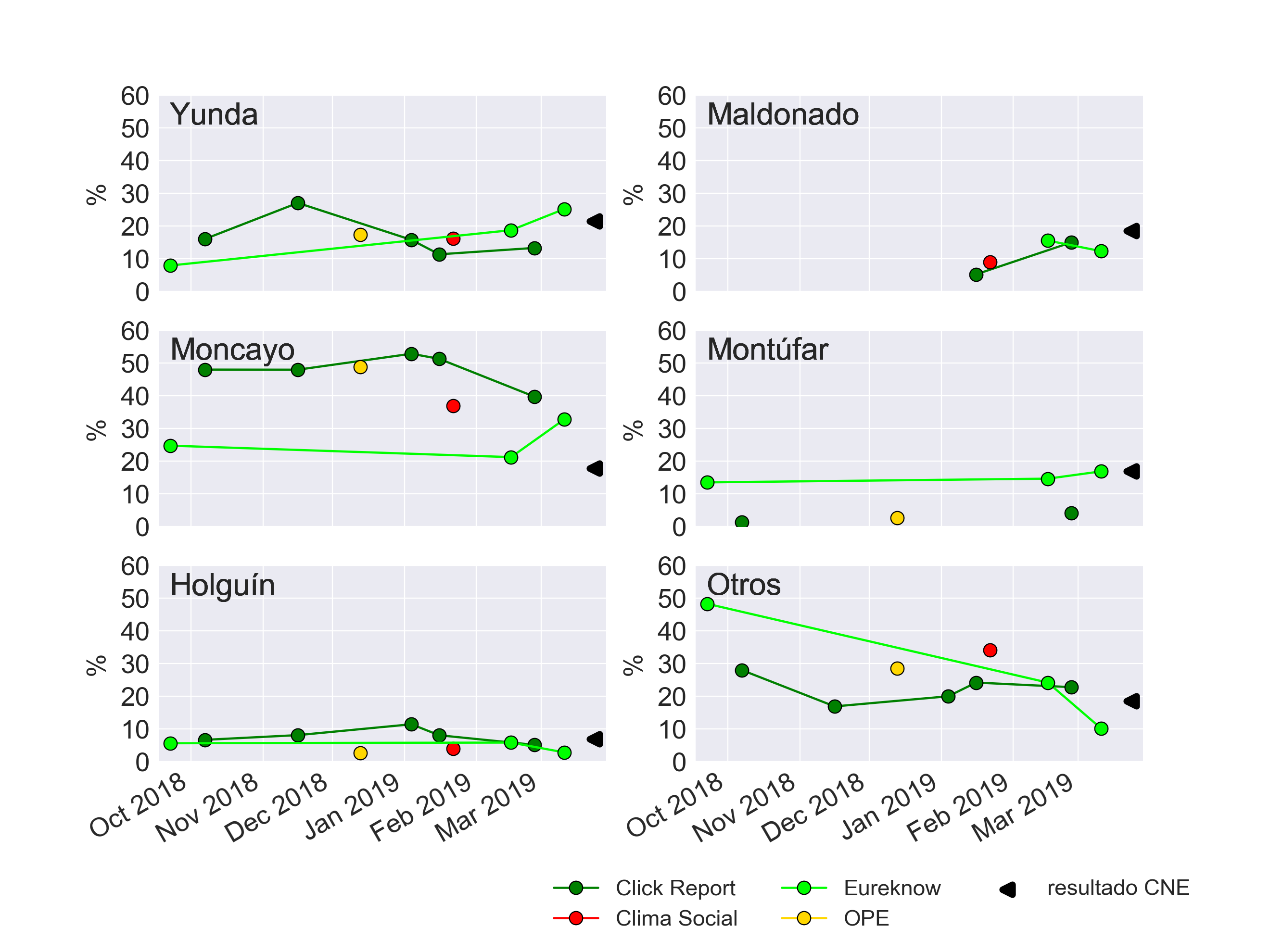
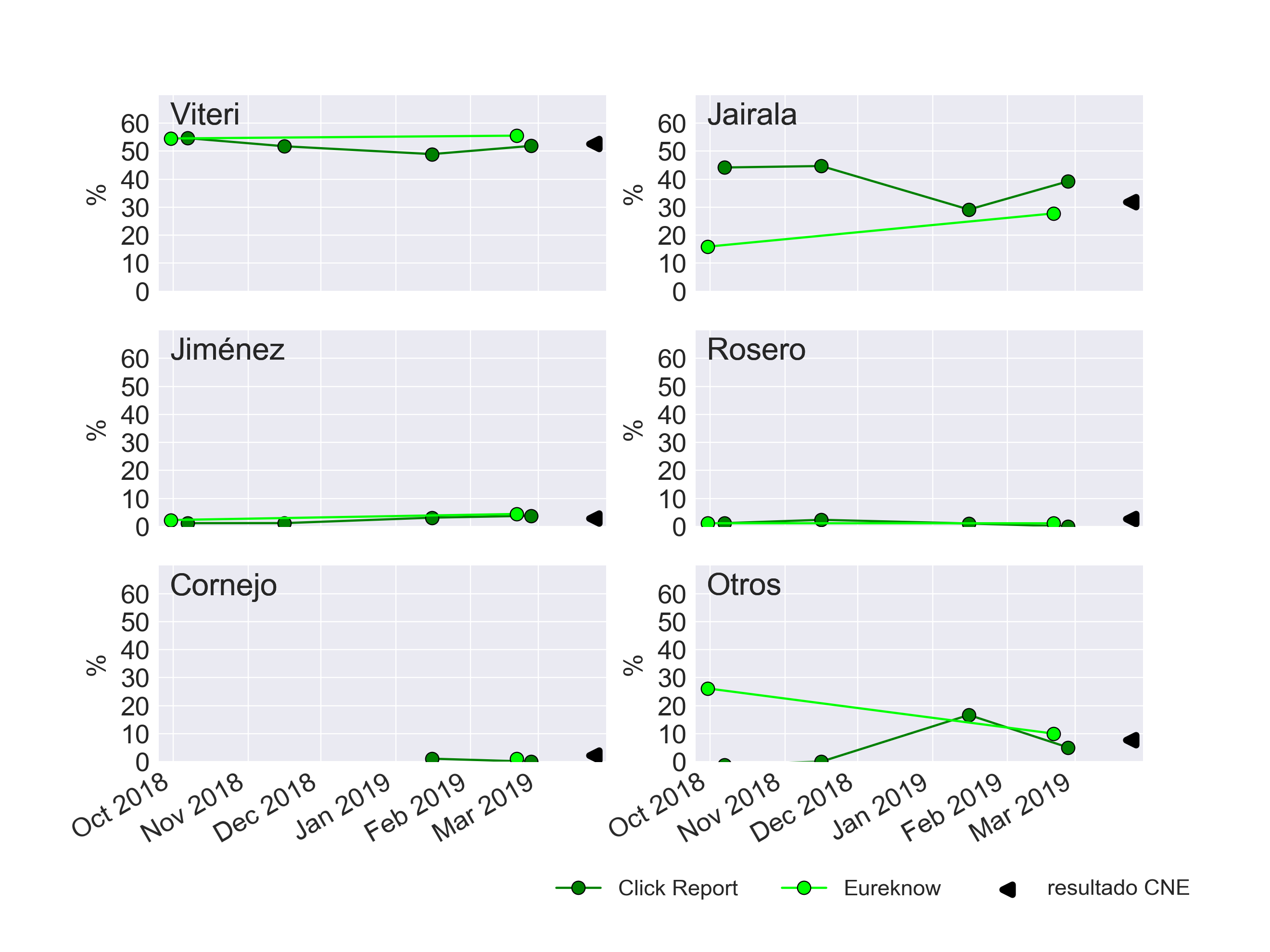
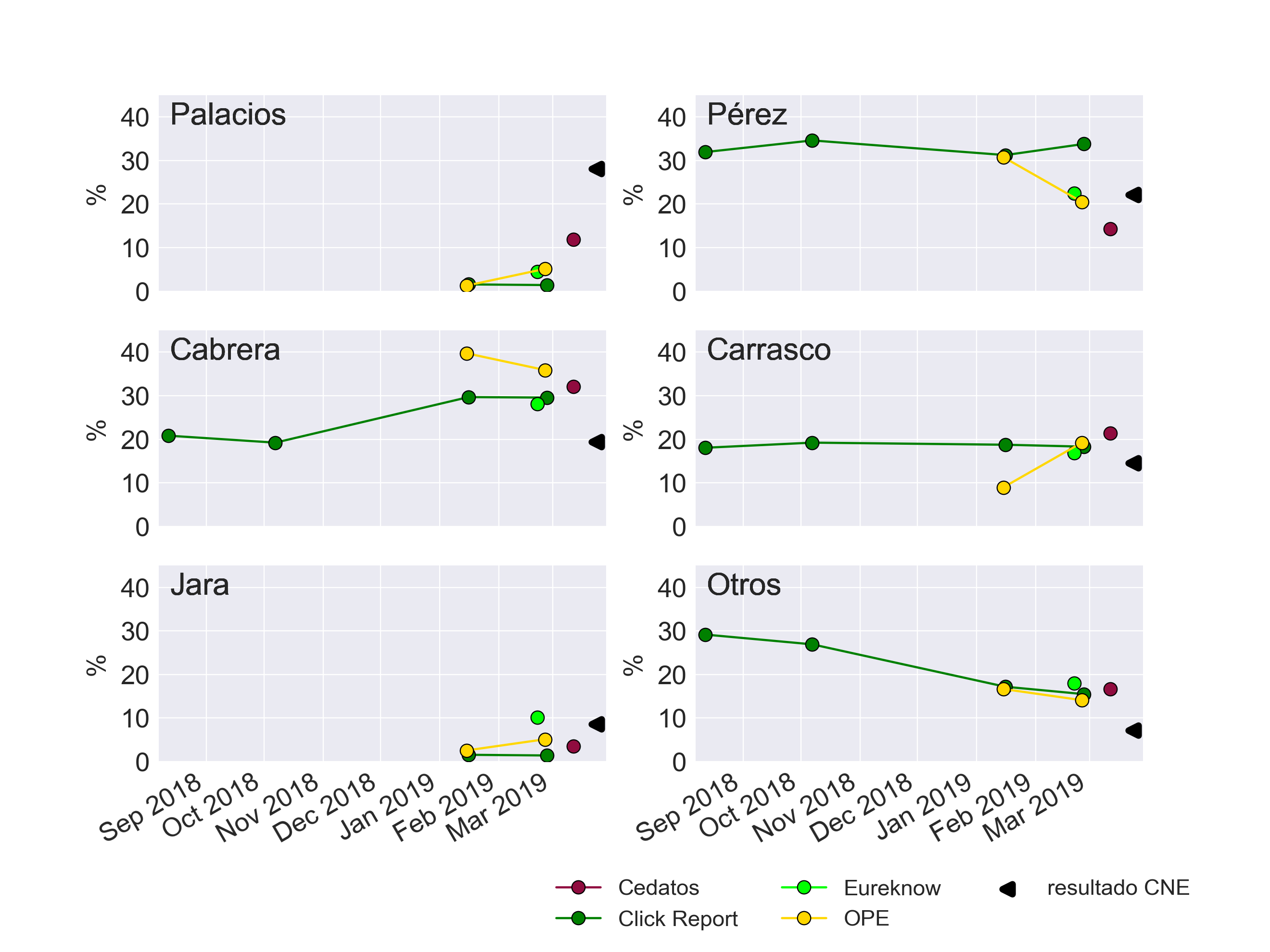
Para evaluar las diferencias porcentuales entre lo que publicaron las encuestas en su última lectura y el resultado oficial del CNE utilizaremos dos criterios: el error absoluto medio (EAM), y el error cuadrático medio (ECM). Con estas métricas podemos analizar tendencias generales por candidato, por encuestadora y en conjunto.
Tanto el EAM o el ECM por sí solos, nos dan un promedio del error de los porcentajes proyectados por la encuestadora con respecto a los resultados oficiales, pero sin considerar si el error proviene de una muy mala estimación de un sólo candidato o pequeños errores en varios candidatos. Es necesario evaluar estos dos errores conjuntamente para tener una mejor idea de la distribución de errores a lo largo de todos los candidatos. El ECM incorpora algunos factores: a) varianza estadística del método empleado por la encuestadora (que se refleja en el margen de error); b) sesgos involuntarios (por ejemplo, sesgo por mala representatividad de las muestras, sesgo de no respuesta, sesgo por voto vergonzante, errores sistemáticos del personal que realiza las encuestas, etc.); c) cambios en la intención de voto de candidatos durante la veda de encuestas; y d) cualquier otro tipo de sesgo malintencionado. En el caso de una encuesta sin sesgos y asumiendo que la foto del momento se ajusta al resultado electoral (que ocurre varios días después), el EAM y el ECM deberían ser muy parecidos y de una magnitud a lo mucho similar al margen de error reportado en la ficha metodológica de la encuestadora.
En Quito, como se puede observar en la Tabla 1, la sobreestimación de Moncayo es mucho mayor que el ECM para todas las encuestadoras. Si el voto decidido a 10 días bordeaba el 60%, esto quiere decir que Moncayo habría perdido todo su apoyo blando (proporcional a los encuestados autoproclamados como indecisos) al final de la campaña. Dicho apoyo pudo haber sido captado por Maldonado, Montúfar y Holguín. Este reordenamiento parece posible al observar que las diferencias entre últimas lecturas y los resultados de Moncayo, Maldonado, Montúfar y Holguín coinciden al menos en dirección (signo) entre encuestadoras. Sin embargo, la gran discrepancia entre encuestadoras con respecto a la intención de voto para Moncayo (como se observa en la Figura 1 para Quito) y la poca coincidencia en el patrón de errores entre encuestadoras (Tabla 1), insinuaría que el argumento de la encuesta como "la foto del momento" es difícil de comprobar ya que cada encuestadora mostró fotos diferentes.
En el caso de Guayaquil, el desempeño de Eureknow ejemplifica el comportamiento de una encuesta en donde sus errores son netamente estadísticos: todas las diferencias por candidato son menores al ME reportado, y el EAM es parecido al ECM.
En Cuenca, la situación de Cabrera es similar a la de Moncayo: habría perdido todo su voto blando en los últimos días de campaña. Carrasco habría sufrido el mismo desgaste pero en menor magnitud. Pérez obtiene una votación que está dentro de la dispersión de resultados de las encuestas, y Palacios habría captado los votos blandos de Cabrera más los de otros candidatos. Nuevamente, es posible, pero difícil de comprobar. Al igual que en Quito, existe poca coincidencia en el patrón de errores entre encuestadoras a pesar de las coincidencias en la dirección de las diferencias entre últimas lecturas y los resultados de Cabrera, Carrasco y Palacios.
En las Tablas 1 podemos observar que para las tres ciudades hay posibles sesgos individuales por candidato y por encuestadora, pero el ejercicio de identificarlos se lo dejamos a ustedes (elementos en donde las diferencias son mucho mayores al ECM de la encuestadora).
En Quito y Cuenca, ninguna de las encuestadoras muestra una distribución de errores simétrica (siendo el ECM bastante mayor que el EAM, y ambos mucho más grandes que el ME), y como hemos discutido, cada encuestadora muestra su propia foto del momento. Aparentemente es posible (aunque parecería improbable), que candidatos pierdan todo su voto blando en los últimos días. Una explicación de los sorpresivos resultados debería también incluir a un voto vergonzante que penetró incluso en el conjunto de encuestados que se declararon como decididos. El cómo tratar al voto indeciso y evitar al voto vergonzante continúa siendo sin duda un gran reto para las casas encuestadoras.
Puntualizamos que este análisis constituye una lectura de lo publicado, de lo que estuvo disponible para un ciudadano promedio en su relación cotidiana con medios de comunicación y encuestadoras durante el periodo descrito. Este análisis no toma en cuenta trabajos de investigación de difusión privada, cuyos resultados pudieran haberse acercado o alejado de los resultados oficiales.
Con respecto a los pronósticos que realizamos en Cálculo Electoral, continuaremos trabajando para incorporar cambios que nos permitan estimar de mejor manera la incertidumbre antes de las elecciones. Algunos de los fenómenos observados en Quito y Cuenca pueden ser cuantificados y parametrizados en nuestros modelos (y esto lo hemos mencionado anteriormente en la metodología)[2]. Como vimos en Cuenca, la probabilidad de que un candidato remonte 20 puntos en los últimos días de campaña no es despreciable, más aún cuando los niveles de indecisión alcanzan a casi la mitad del electorado.
[1] Esta úlitma léctura fue difundida antes de que se definan los candidatos finales y antes de que empiece oficialmente la campaña electoral.
[2] Consideraremos en un futuro utilizar distribuciones t, ya que teóricamente son más apropiadas cuando las muestras son pequeñas. Además, estas tienen colas más largas que una distribución normal, o una beta (particularmente las distribuciones t con pocos grados de libertad). En este momento es difícil decidir el número de grados de libertad que se debe emplear, ya que no tenemos suficientes datos para saber cómo se comporta la cola de la distribución. Por ejemplo, ¿cuál es la probabilidad de que un candidato que va perdiendo por 20 puntos en las encuestas termine ganando la elección? La respuesta podría cambiar por varios ordenes de magnitud (1, 0.1 ó 0.01% chances de ganar) dependiendo de cuantos grados de libertad se utilicen en la distribución t. Una distribución t bien parametrizada ayudaría a modelar de mejor manera estos casos extremos.